
Click here to go to the corresponding page for the latest version of DIALS
Multi-crystal analysis with DIALS and BLEND¶
Introduction¶
BLEND is a CCP4 program for analysis of multiple data sets. It attempts to identify isomorphous clusters that may be scaled and merged together to form a more complete multi-crystal dataset. Clustering in blend is based on the refined cell parameters from integration, so it is important that these are determined accurately. Unfortunately, for narrow wedges of data (where BLEND is most useful) cell refinement may be complicated by issues such as the high correlation between e.g. the detector distance and the cell volume.
One solution is to fix detector parameters during cell refinement so that the detector is the same for every dataset processed. However, this is only feasible if an accurate detector model is determined ahead of time, which might require the use of a well-diffracting sacrificial crystal. If we only have the narrow wedges of data available then it is more complicated to determine what the best detector model would be to fix.
If we can make the assumption that the beam and detector did not move during and between all of the datasets we collected then we can use DIALS joint refinement to refine all of the crystal cells at the same time, simultaneously with shared detector and beam models.
In this tutorial, we will attempt to do that for 73 sweeps of data collected from crystals of TehA, a well-diffracting integral membrane protein measured using in situ diffraction from crystallisation plates at room temperature. Each sweep provides between 4 and 10 degrees of data.
This tutorial is relatively advanced in that it requires high level scripting of the DIALS command line programs, however candidate scripts are provided and the tutorial will hopefully be easy enough to follow.
Individual processing¶
We start with a directory full of images. It is easy enough to figure out
which files belong with which sweep from the filename templates, however note
that the pattern between templates is not totally consistent. Most of the sweeps
start with the prefix xtal, but some have just xta. One way of
getting around this annoyance would be to use the fact that each dataset has
a single *.log file associated with it and identify the different
datasets that way. However, we would prefer to come up with a protocol that
would work more generally, not just for the TehA data. Happily we can just
let DIALS figure it out for us:
dials.import /path/to/TehA/*.cbf
The following parameters have been modified:
input {
datablock = <image files>
}
--------------------------------------------------------------------------------
DataBlock 0
format: <class 'dxtbx.format.FormatCBFMiniPilatus.FormatCBFMiniPilatus'>
num images: 2711
num sweeps: 73
num stills: 0
--------------------------------------------------------------------------------
Writing datablocks to datablock.json
With a single command we have determined that there are 73 individual sweeps comprising 2711 total images. Running the following command will give us information about each one of these datasets:
dials.show datablock.json
That was a smooth start, but now things get abruptly more difficult. Before we perform the joint analysis, we want to do the individual analysis to compare to. This will also give us intermediate files so that we don’t have to start from scratch when setting up the joint refinement job. Essentially we just want to run a sequence of DIALS commands to process each recorded sweep. However we can’t (currently) split the datablock into individual sweeps with a single command. We will have to start again with dials.import for each sweep individually - but we really don’t want to run this manually 73 times.
The solution is to write a script that will take the datablock.json as
input, extract the filename templates, and run the same processing commands
for each dataset. This script could be written in BASH, tcsh, perl,
ruby - whatever you feel most comfortable with. However here we will use Python,
or more specifically dials.python because we will take advantage of
features in the cctbx to make it easy to write scripts that take advantage
of parallel execution.
Also we would like to read datablock.json with the DIALS API rather than
extracting the sweep templates using something like grep.
The script we used to do this is reproduced below. You can copy this into a file,
save it as process_TehA.py and then run it as follows:
time dials.python process_TehA.py datablock.json
On a Linux desktop with a Core i7 CPU running at 3.07GHz the script took about 8
minutes to run (though file i/o is a significant factor)
and successfully processed 41 datasets. If time is short, you
might like to start running it now before reading the description of what the
script does. If time is really short then try uncommenting the line
tasklist = tasklist[0:35] to reduce the number of datasets processed.:
#!/bin/env dials.python
import os
import sys
import glob
from libtbx import easy_run, easy_mp
from dxtbx.datablock import DataBlockFactory
from dials.test import cd
def process_sweep(task):
"""Process a single sweep of data. The parameter 'task' will be a
tuple, the first element of which is an integer job number and the
second is the filename template of the images to process"""
num = task[0]
template = task[1]
# create directory
with cd("sweep_%02d" % num):
cmd = "dials.import template={0}".format(template)
easy_run.fully_buffered(command=cmd)
easy_run.fully_buffered(command="dials.find_spots datablock.json")
# initial indexing in P 1
cmd = "dials.index datablock.json strong.pickle " +\
"output.experiments=P1_experiments.json"
easy_run.fully_buffered(command=cmd)
if not os.path.isfile("P1_experiments.json"):
print "Job %02d failed in initial indexing" % num
return
# bootstrap from the refined P 1 cell
cmd = "dials.index P1_experiments.json strong.pickle space_group='H 3'"
easy_run.fully_buffered(command=cmd)
if not os.path.isfile("experiments.json"):
print "Job %02d failed in indexing" % num
return
# static model refinement
cmd = "dials.refine experiments.json indexed.pickle " + \
"outlier.algorithm=tukey use_all_reflections=true"
easy_run.fully_buffered(command=cmd)
if not os.path.isfile("refined_experiments.json"):
print "Job %02d failed in refinement" % num
return
# WARNING! Fast and dirty integration.
# Do not use the result for scaling/merging!
cmd = "dials.integrate refined_experiments.json indexed.pickle " + \
"profile.fitting=False prediction.dmin=8.0 prediction.dmax=8.1"
easy_run.fully_buffered(command=cmd)
if not os.path.isfile("integrated.pickle"):
print "Job %02d failed during integration" % num
return
# create MTZ
cmd = "dials.export refined_experiments.json integrated.pickle " +\
"mtz.hklout=integrated.mtz"
easy_run.fully_buffered(command=cmd)
if not os.path.isfile("integrated.mtz"):
print "Job %02d failed during MTZ export" % num
return
# if we got this far, return the path to the MTZ
return "sweep_%02d/integrated.mtz" % num
if __name__ == "__main__":
if len(sys.argv) != 2:
sys.exit("Usage: dials.python process_TehA.py datablock.json")
datablock_path = os.path.abspath(sys.argv[1])
datablock = DataBlockFactory.from_serialized_format(datablock_path,
check_format=False)[0]
sweeps = datablock.extract_sweeps()
templates = [e.get_template() for e in sweeps]
tasklist = list(enumerate(sorted(templates)))
if len(tasklist) == 0: sys.exit("No images found!")
# uncomment the following line if short on time!
#tasklist = tasklist[0:35]
from libtbx import Auto
nproc = easy_mp.get_processes(Auto)
print "Attempting to process the following datasets, with {} processes".format(nproc)
for task in tasklist:
print "%d: %s" % task
results = easy_mp.parallel_map(
func=process_sweep,
iterable=tasklist,
processes=nproc,
preserve_order=True)
good_results = [e for e in results if e is not None]
print "Successfully created the following MTZs:"
for result in good_results:
print result
We will now describe what is in this script. The first lines are
just imports to bring in modules from the Python standard library as well as
easy_run and easy_mp from libtbx (part of cctbx),
DataBlockFactory from dxtbx to read in the datablock and
a class from the dials.test package that simplifies running commands in
a new directory. Following that is a definition for the function
process_sweep which will perform all the steps required to process one
dataset from images to unmerged MTZ. The code block under:
if __name__ == "__main__":
are the lines that are executed when the script starts. First we check that the
script has been passed a path to a datablock. We then extract the 73 sweeps
from this into a list, then get the filename templates from each element in the
list. We associate each of these templates with a number to form a list of
‘tasks’ to pass into process_sweep, but instead
of doing this in serial we can use easy_mp to run in parallel. This will
be okay because inside process_sweep, we ensure that all results are
written into a new directory. First we use a facility of the easy_mp
module to determine the number of processes to run in parallel and then we submit
the job with parallel_map.
Within process_sweep all external commands are run within a with
block where execution is controlled by the context manager cd. If you
want the gory details, they are here.
Essentially this is a way to write clean code that tidies up after itself
properly. In this case, we will create a new directory, execute commands in that
directory, then change back to the old directory afterwards. If the directory
already exists, this will fail with an error.
The commands that are run inside the managed block are usual dials commands,
familiar from other tutorials. There are a couple of interesting points
to note though. We know that the correct space group is H 3, but it turns out
that if we ask dials.index to find an H 3 cell right from the start
then many of the sweeps fail to index. This is simply because the initial models
contained in datablock.json are too poor to locate a cell with the
symmetry constraints. However, for many of the sweeps the indexing program will
refine the P 1 solution to the correct cell. For this reason we first run
indexing in P 1:
dials.index datablock.json strong.pickle output.experiments=P1_experiments.json
and then we feed the refined P1_experiments.json back into
dials.index specifying the correct symmetry:
dials.index P1_experiments.json strong.pickle space_group='H 3'
When dials.index is passed an experiments.json containing
a crystal model rather than just a databock.json then it automatically
uses a known_orientation indexer, which avoids doing the basis vector
search again. It uses the basis of the refined P 1 cell and just assigns
indices under the assumption of H 3 symmetry. The symmetry constraints are
then enforced during the refinement steps carried out by dials.index.
This procedure gives us a greater success rate of indexing in H 3, and required
no manual intervention.
Following indexing we do scan-static cell refinement:
dials.refine experiments.json indexed.pickle outlier.algorithm=tukey use_all_reflections=true
Outlier rejection was switched on in an attempt to avoid any zingers or other
errant spots from affecting our refined cells. Without analysing the data closer
it is not clear whether there are any particularly bad outliers here. We could repeat
the whole analysis with this switched off if we want to investigate more closely,
or look through all the dials.refine.log files to see results of the
outlier rejection step.
We elected use all reflections rather than taking a random subset because these are narrow wedges and there are few reflections anyway. Taking a random subset is only a time-saving procedure, and it won’t provide much benefit here anyway.
We don’t bother with the time-consuming step of scan-varying refinement, because it is the scan-static cell that will be written into the MTZ header. Scan- varying refinement would give us better models for integration but as we will only be running blend in ‘analysis’ mode we are in the unusual situation of not actually caring what the intensities are. In this case, the MTZ file is just a carrier for the globally refined unit cell!
Following refinement we integrate the data in a very quick and dirty way, simply to get an MTZ file as fast as possible. This is a terrible way to integrate data usually!:
dials.integrate refined_experiments.json indexed.pickle profile.fitting=False prediction.dmin=8.0 prediction.dmax=8.1
The profile.fitting=False option ensures we only do summation integration,
no profile fitting, while the prediction.dmin=8.0 and
prediction.dmax=8.1 options only integrate data between 8.0 and 8.1 Angstroms.
As a result very few reflections will be integrated. The MTZ file here is just
being used as a carrier of the cell information into blend. By restricting the
resolution range this way we are making it obvious that the content of the file
is useless for any other purpose.
Warning
Do not use the data produced by this script for scaling and merging. More careful processing should be done first!
Finally we use dials.export to create an MTZ file:
dials.export refined_experiments.json integrated.pickle mtz.hklout=integrated.mtz
After each of these major steps we check whether the last command ran successfully
by checking for the existence of an expected output file. If the file does not
exist we make no effort to rescue the dataset, we just return early from the
process_sweep function, freeing up a process so that
parallel_map can start up the next.
Here is the output of a run of the script:
Attempting to process the following datasets, with 5 processes
0: /home/david/xray/TehA/xta30_1_####.cbf
1: /home/david/xray/TehA/xta31_1_####.cbf
2: /home/david/xray/TehA/xta32_1_####.cbf
3: /home/david/xray/TehA/xta33_1_####.cbf
4: /home/david/xray/TehA/xta34_1_####.cbf
5: /home/david/xray/TehA/xta9_1_####.cbf
6: /home/david/xray/TehA/xta9_2_####.cbf
7: /home/david/xray/TehA/xtal10_1_####.cbf
8: /home/david/xray/TehA/xtal11_1_####.cbf
9: /home/david/xray/TehA/xtal12_1_####.cbf
10: /home/david/xray/TehA/xtal12_2_####.cbf
11: /home/david/xray/TehA/xtal13_1_####.cbf
12: /home/david/xray/TehA/xtal14_1_####.cbf
13: /home/david/xray/TehA/xtal15_1_####.cbf
14: /home/david/xray/TehA/xtal16_1_####.cbf
15: /home/david/xray/TehA/xtal17_1_####.cbf
16: /home/david/xray/TehA/xtal18_1_####.cbf
17: /home/david/xray/TehA/xtal19_1_####.cbf
18: /home/david/xray/TehA/xtal1_1_####.cbf
19: /home/david/xray/TehA/xtal20_1_####.cbf
20: /home/david/xray/TehA/xtal21_1_####.cbf
21: /home/david/xray/TehA/xtal22_1_####.cbf
22: /home/david/xray/TehA/xtal23_1_####.cbf
23: /home/david/xray/TehA/xtal24_1_####.cbf
24: /home/david/xray/TehA/xtal25_1_####.cbf
25: /home/david/xray/TehA/xtal26_1_####.cbf
26: /home/david/xray/TehA/xtal26_2_####.cbf
27: /home/david/xray/TehA/xtal27_1_####.cbf
28: /home/david/xray/TehA/xtal28_1_####.cbf
29: /home/david/xray/TehA/xtal29_1_####.cbf
30: /home/david/xray/TehA/xtal2_1_####.cbf
31: /home/david/xray/TehA/xtal35_1_####.cbf
32: /home/david/xray/TehA/xtal36_1_####.cbf
33: /home/david/xray/TehA/xtal37_1_####.cbf
34: /home/david/xray/TehA/xtal37_2_####.cbf
35: /home/david/xray/TehA/xtal38_1_####.cbf
36: /home/david/xray/TehA/xtal39_1_####.cbf
37: /home/david/xray/TehA/xtal3_2_####.cbf
38: /home/david/xray/TehA/xtal40_1_####.cbf
39: /home/david/xray/TehA/xtal40_2_####.cbf
40: /home/david/xray/TehA/xtal40_3_####.cbf
41: /home/david/xray/TehA/xtal40_4_####.cbf
42: /home/david/xray/TehA/xtal41_1_####.cbf
43: /home/david/xray/TehA/xtal42_1_####.cbf
44: /home/david/xray/TehA/xtal43_1_####.cbf
45: /home/david/xray/TehA/xtal44_1_####.cbf
46: /home/david/xray/TehA/xtal45_1_####.cbf
47: /home/david/xray/TehA/xtal46_1_####.cbf
48: /home/david/xray/TehA/xtal47_1_####.cbf
49: /home/david/xray/TehA/xtal48_1_####.cbf
50: /home/david/xray/TehA/xtal49_1_####.cbf
51: /home/david/xray/TehA/xtal4_3_####.cbf
52: /home/david/xray/TehA/xtal50_1_####.cbf
53: /home/david/xray/TehA/xtal50_2_####.cbf
54: /home/david/xray/TehA/xtal51_1_####.cbf
55: /home/david/xray/TehA/xtal52_1_####.cbf
56: /home/david/xray/TehA/xtal53_1_####.cbf
57: /home/david/xray/TehA/xtal54_1_####.cbf
58: /home/david/xray/TehA/xtal55_1_####.cbf
59: /home/david/xray/TehA/xtal55_2_####.cbf
60: /home/david/xray/TehA/xtal56_1_####.cbf
61: /home/david/xray/TehA/xtal56_2_####.cbf
62: /home/david/xray/TehA/xtal57_1_####.cbf
63: /home/david/xray/TehA/xtal58_1_####.cbf
64: /home/david/xray/TehA/xtal58_2_####.cbf
65: /home/david/xray/TehA/xtal58_3_####.cbf
66: /home/david/xray/TehA/xtal59_1_####.cbf
67: /home/david/xray/TehA/xtal5_1_####.cbf
68: /home/david/xray/TehA/xtal60_1_####.cbf
69: /home/david/xray/TehA/xtal60_2_####.cbf
70: /home/david/xray/TehA/xtal6_1_####.cbf
71: /home/david/xray/TehA/xtal7_1_####.cbf
72: /home/david/xray/TehA/xtal8_1_####.cbf
Job 04 failed in indexing
Job 06 failed in initial indexing
Job 07 failed in indexing
Job 08 failed in indexing
Job 11 failed in indexing
Job 10 failed in indexing
Job 13 failed in indexing
Job 12 failed in indexing
Job 15 failed in initial indexing
Job 21 failed in initial indexing
Job 20 failed in initial indexing
Job 32 failed in initial indexing
Job 37 failed in indexing
Job 35 failed in indexing
Job 38 failed in indexing
Job 39 failed in indexing
Job 41 failed in indexing
Job 40 failed in indexing
Job 45 failed in indexing
Job 44 failed in indexing
Job 47 failed in indexing
Job 52 failed in initial indexing
Job 49 failed in initial indexing
Job 55 failed in initial indexing
Job 57 failed in initial indexing
Job 61 failed in indexing
Job 62 failed in indexing
Job 69 failed in indexing
Job 70 failed in indexing
Job 68 failed in indexing
Job 71 failed in initial indexing
Job 72 failed in indexing
Successfully created the following MTZs:
sweep_00/integrated.mtz
sweep_01/integrated.mtz
sweep_02/integrated.mtz
sweep_03/integrated.mtz
sweep_05/integrated.mtz
sweep_09/integrated.mtz
sweep_14/integrated.mtz
sweep_16/integrated.mtz
sweep_17/integrated.mtz
sweep_18/integrated.mtz
sweep_19/integrated.mtz
sweep_22/integrated.mtz
sweep_23/integrated.mtz
sweep_24/integrated.mtz
sweep_25/integrated.mtz
sweep_26/integrated.mtz
sweep_27/integrated.mtz
sweep_28/integrated.mtz
sweep_29/integrated.mtz
sweep_30/integrated.mtz
sweep_31/integrated.mtz
sweep_33/integrated.mtz
sweep_34/integrated.mtz
sweep_36/integrated.mtz
sweep_42/integrated.mtz
sweep_43/integrated.mtz
sweep_46/integrated.mtz
sweep_48/integrated.mtz
sweep_50/integrated.mtz
sweep_51/integrated.mtz
sweep_53/integrated.mtz
sweep_54/integrated.mtz
sweep_56/integrated.mtz
sweep_58/integrated.mtz
sweep_59/integrated.mtz
sweep_60/integrated.mtz
sweep_63/integrated.mtz
sweep_64/integrated.mtz
sweep_65/integrated.mtz
sweep_66/integrated.mtz
sweep_67/integrated.mtz
real 7m45.656s
user 25m32.532s
sys 1m34.090s
Analysis of individually processed datasets¶
The paths to integrated.mtz files can be copied directly into a file,
say individual_mtzs.dat, and passed to blend for analysis:
echo "END" | blend -a individual_mtzs.dat
The dendrogram resulting from clustering is shown here:
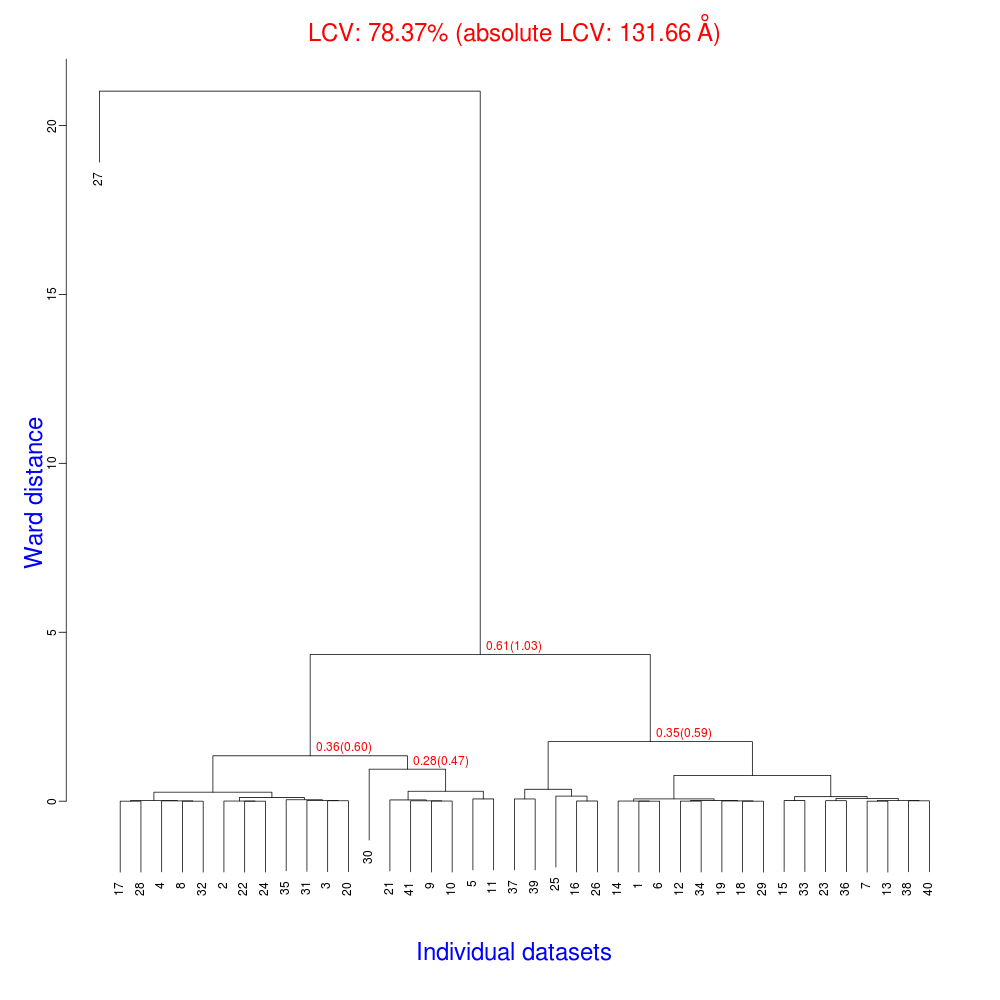
Immediately the dendrogram shows that dataset 27 is an extreme outlier.
From FINAL_list_of_files.dat we can see that this refers to
sweep_46/integrated.mtz.
As we kept all the dials .log files
from DIALS processing we could investigate this further, however as this is
only one sweep out of 41, we decide just to throw it away and
move on. So, edit individual_mtzs.dat to remove
the line sweep_46/integrated.mtz
and rerun blend.
Now the dendrogram looks better:
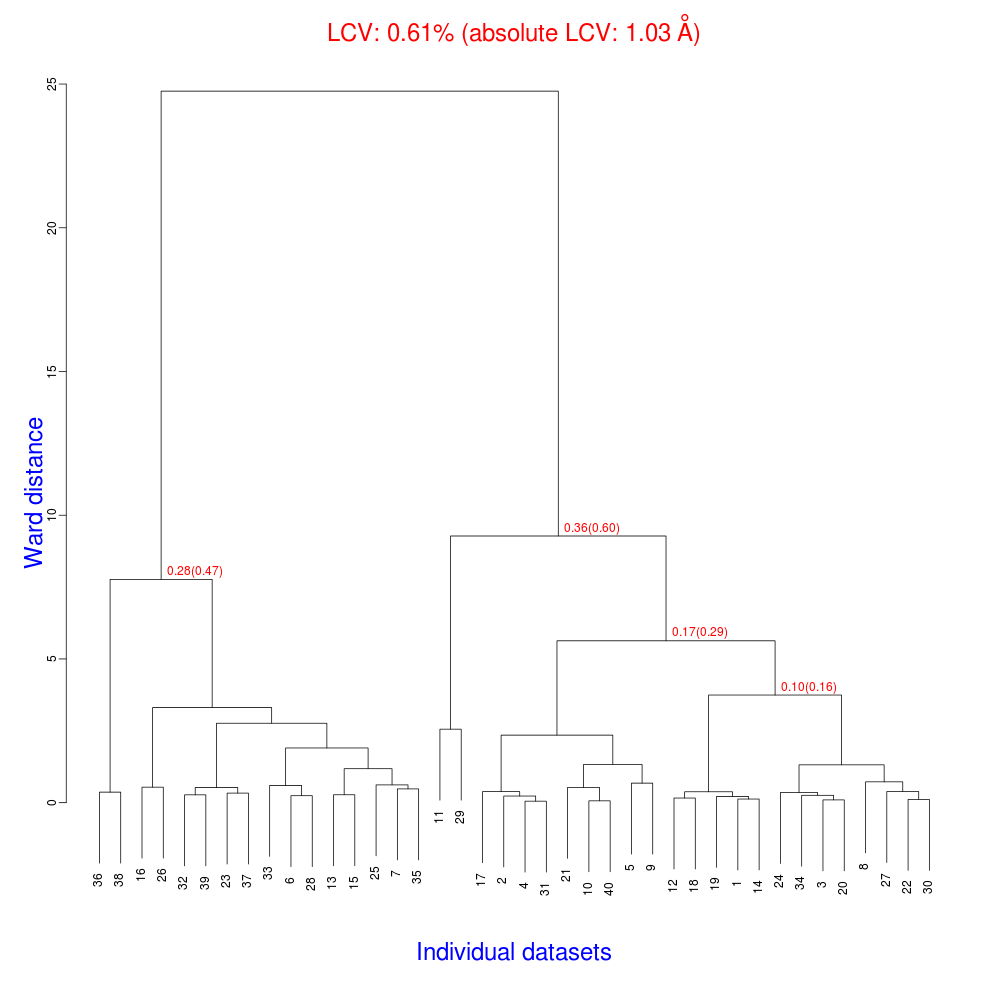
The Linear Cell Variation (LCV) is now less than 1%, with an absolute value of 1.03 Angstroms, indicating good isomorphism amongst all the remaining datasets.
Joint refinement¶
Now that we have done the BLEND analysis for individually processed datasets, we would like to do joint refinement of the crystals to reduce correlations between the detector or beam parameters with individual crystals. As motivation we may look at these correlations for one of these datasets. For example:
cd sweep_00
dials.refine experiments.json indexed.pickle \
track_parameter_correlation=true correlation_plot.filename=corrplot.png
cd ..
The new file sweep_00/corrplot.png shows correlations between parameters
refined with this single 8 degree dataset. Clearly parameters like the
detector distance and the crystal metrical matrix parameters are highly
correlated.
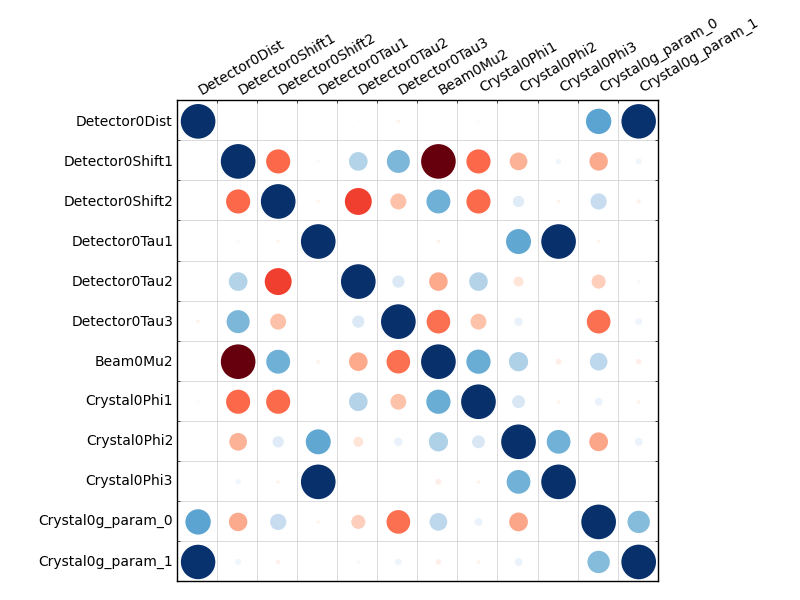
Although the DIALS toolkit has a sophisticated mechanism for modelling
multi-experiment data, the user interface for handling such data is still
rather limited. In order to do joint refinement of the sweeps we need to combine them
into a single multi-experiment experiments.json and corresponding
reflections.pickle. Whilst doing this we want to reduce the separate
detector, beam and goniometer models for each experiment into a single shared
model of each type. The program dials.combine_experiments can
be used for this, but first we have to prepare an input file with a text editor
listing the individual sweeps in order. We can use
individual_mtzs.dat as a template to start with. In our case the final
file looks like this:
input {
experiments = "sweep_00/refined_experiments.json"
experiments = "sweep_01/refined_experiments.json"
experiments = "sweep_02/refined_experiments.json"
experiments = "sweep_03/refined_experiments.json"
experiments = "sweep_05/refined_experiments.json"
experiments = "sweep_09/refined_experiments.json"
experiments = "sweep_14/refined_experiments.json"
experiments = "sweep_16/refined_experiments.json"
experiments = "sweep_17/refined_experiments.json"
experiments = "sweep_18/refined_experiments.json"
experiments = "sweep_19/refined_experiments.json"
experiments = "sweep_22/refined_experiments.json"
experiments = "sweep_23/refined_experiments.json"
experiments = "sweep_24/refined_experiments.json"
experiments = "sweep_25/refined_experiments.json"
experiments = "sweep_26/refined_experiments.json"
experiments = "sweep_27/refined_experiments.json"
experiments = "sweep_28/refined_experiments.json"
experiments = "sweep_29/refined_experiments.json"
experiments = "sweep_30/refined_experiments.json"
experiments = "sweep_31/refined_experiments.json"
experiments = "sweep_33/refined_experiments.json"
experiments = "sweep_34/refined_experiments.json"
experiments = "sweep_36/refined_experiments.json"
experiments = "sweep_42/refined_experiments.json"
experiments = "sweep_43/refined_experiments.json"
experiments = "sweep_48/refined_experiments.json"
experiments = "sweep_50/refined_experiments.json"
experiments = "sweep_51/refined_experiments.json"
experiments = "sweep_53/refined_experiments.json"
experiments = "sweep_54/refined_experiments.json"
experiments = "sweep_56/refined_experiments.json"
experiments = "sweep_58/refined_experiments.json"
experiments = "sweep_59/refined_experiments.json"
experiments = "sweep_60/refined_experiments.json"
experiments = "sweep_63/refined_experiments.json"
experiments = "sweep_64/refined_experiments.json"
experiments = "sweep_65/refined_experiments.json"
experiments = "sweep_66/refined_experiments.json"
experiments = "sweep_67/refined_experiments.json"
reflections = "sweep_00/indexed.pickle"
reflections = "sweep_01/indexed.pickle"
reflections = "sweep_02/indexed.pickle"
reflections = "sweep_03/indexed.pickle"
reflections = "sweep_05/indexed.pickle"
reflections = "sweep_09/indexed.pickle"
reflections = "sweep_14/indexed.pickle"
reflections = "sweep_16/indexed.pickle"
reflections = "sweep_17/indexed.pickle"
reflections = "sweep_18/indexed.pickle"
reflections = "sweep_19/indexed.pickle"
reflections = "sweep_22/indexed.pickle"
reflections = "sweep_23/indexed.pickle"
reflections = "sweep_24/indexed.pickle"
reflections = "sweep_25/indexed.pickle"
reflections = "sweep_26/indexed.pickle"
reflections = "sweep_27/indexed.pickle"
reflections = "sweep_28/indexed.pickle"
reflections = "sweep_29/indexed.pickle"
reflections = "sweep_30/indexed.pickle"
reflections = "sweep_31/indexed.pickle"
reflections = "sweep_33/indexed.pickle"
reflections = "sweep_34/indexed.pickle"
reflections = "sweep_36/indexed.pickle"
reflections = "sweep_42/indexed.pickle"
reflections = "sweep_43/indexed.pickle"
reflections = "sweep_48/indexed.pickle"
reflections = "sweep_50/indexed.pickle"
reflections = "sweep_51/indexed.pickle"
reflections = "sweep_53/indexed.pickle"
reflections = "sweep_54/indexed.pickle"
reflections = "sweep_56/indexed.pickle"
reflections = "sweep_58/indexed.pickle"
reflections = "sweep_59/indexed.pickle"
reflections = "sweep_60/indexed.pickle"
reflections = "sweep_63/indexed.pickle"
reflections = "sweep_64/indexed.pickle"
reflections = "sweep_65/indexed.pickle"
reflections = "sweep_66/indexed.pickle"
reflections = "sweep_67/indexed.pickle"
}
We called this file experiments_and_reflections.phil then run
dials.combine_experiments like this:
dials.combine_experiments experiments_and_reflections.phil \
reference_from_experiment.beam=0 \
reference_from_experiment.goniometer=0 \
reference_from_experiment.detector=0
The reference_from_experiment options tell the program to replace all
beam, goniometer and detector models in the input experiments with those
models taken from the first experiment, i.e. experiment ‘0’ using 0-based
indexing. The output lists the number of reflections in each sweep contributing
to the final combined_reflections.pickle:
---------------------
| Experiment | Nref |
---------------------
| 0 | 1446 |
| 1 | 1422 |
| 2 | 1209 |
| 3 | 1376 |
| 4 | 452 |
| 5 | 1664 |
| 6 | 1528 |
| 7 | 1448 |
| 8 | 1275 |
| 9 | 239 |
| 10 | 1614 |
| 11 | 1052 |
| 12 | 1845 |
| 13 | 1495 |
| 14 | 2041 |
| 15 | 1308 |
| 16 | 1839 |
| 17 | 1828 |
| 18 | 1644 |
| 19 | 243 |
| 20 | 1061 |
| 21 | 2416 |
| 22 | 1885 |
| 23 | 949 |
| 24 | 3569 |
| 25 | 2967 |
| 26 | 935 |
| 27 | 1329 |
| 28 | 650 |
| 29 | 1325 |
| 30 | 633 |
| 31 | 1233 |
| 32 | 2131 |
| 33 | 2094 |
| 34 | 2141 |
| 35 | 1661 |
| 36 | 2544 |
| 37 | 2227 |
| 38 | 982 |
| 39 | 1138 |
---------------------
Saving combined experiments to combined_experiments.json
Saving combined reflections to combined_reflections.pickle
We may also inspect the contents of combined_experiments.json, by using
dials.show, for example:
dials.show combined_experiments.json
Useful though this is, it is clear how this could become unwieldy as the number of experiments increases. Work on better interfaces to multi-crystal (or generally, multi-experiment) data is ongoing within the DIALS project. Suggestions are always welcome!
Now we have the joint experiments and reflections files we can run our multi- crystal refinement job. First we try outlier rejection, so that the refinement run is similar to the jobs we ran on individual datasets:
dials.refine combined_experiments.json combined_reflections.pickle \
use_all_reflections=true outlier.algorithm=tukey
The following parameters have been modified:
refinement {
reflections {
outlier {
algorithm = null *tukey
}
}
}
input {
experiments = combined_experiments.json
reflections = combined_reflections.pickle
}
Configuring refiner
Summary statistics for observations matched to predictions:
---------------------------------------------------------------------
| | Min | Q1 | Med | Q3 | Max |
---------------------------------------------------------------------
| Xc - Xo (mm) | -14.68 | -0.8191 | -0.0739 | 0.7823 | 15.85 |
| Yc - Yo (mm) | -21.75 | -0.5103 | -0.01936 | 0.4596 | 17.19 |
| Phic - Phio (deg) | -17.36 | -0.2058 | 0.0004136 | 0.2091 | 28.12 |
| X weights | 233 | 359.2 | 379.4 | 392.9 | 405.6 |
| Y weights | 264.7 | 392.9 | 401.3 | 404.4 | 405.6 |
| Phi weights | 177 | 299.9 | 300 | 300 | 300 |
---------------------------------------------------------------------
16559 reflections have been rejected as outliers
Traceback (most recent call last):
File "/home/david/bsx/cctbx-svn/build/../sources/dials/command_line/refine.py", line 370, in <module>
halraiser(e)
File "/home/david/bsx/cctbx-svn/build/../sources/dials/command_line/refine.py", line 368, in <module>
script.run()
File "/home/david/bsx/cctbx-svn/build/../sources/dials/command_line/refine.py", line 274, in run
reflections, experiments)
File "/home/david/bsx/cctbx-svn/sources/dials/algorithms/refinement/refiner.py", line 340, in from_parameters_data_experiments
verbosity=verbosity)
File "/home/david/bsx/cctbx-svn/sources/dials/algorithms/refinement/refiner.py", line 585, in _build_components
target = cls.config_target(params, experiments, refman, pred_param, do_stills)
File "/home/david/bsx/cctbx-svn/sources/dials/algorithms/refinement/refiner.py", line 1008, in config_target
options.jacobian_max_nref)
File "/home/david/bsx/cctbx-svn/sources/dials/algorithms/refinement/target.py", line 404, in __init__
self._reflection_manager.finalise()
File "/home/david/bsx/cctbx-svn/sources/dials/algorithms/refinement/reflection_manager.py", line 237, in finalise
self._check_too_few()
File "/home/david/bsx/cctbx-svn/sources/dials/algorithms/refinement/reflection_manager.py", line 262, in _check_too_few
raise RuntimeError(msg)
RuntimeError: Please report this error to dials-support@lists.sourceforge.net: Remaining number of reflections = 8, for experiment 19, which is below the configured limit for this reflection manager
Oops! That wasn’t good. Looking at the error we see that experiment 19 provides
only 8 reflections to refinement, which is disallowed by a default
parameters of dials.refine, namely minimum_number_of_reflections=20.
But from the output of dials.combine_experiments we see that experiment
19 has 243 indexed reflections. What happened? Well, forcing the individual
experiments to share the beam and detector models of experiment 0 has led to some
very poor predictions for some of these experiments. See the Summary statistics
table, where the worst positional residuals are greater than 20 mm! We may put this
down to the very narrow wedges of data we have. Experiment 19 is one of the
narrowest, with only 4 degrees of data. Outlier rejection is not a good idea here
because it selectively removes reflections from the worst fitting experiments.
Instead we try without outlier rejection:
dials.refine combined_experiments.json combined_reflections.pickle \
use_all_reflections=true \
output.experiments=refined_combined_experiments.json
This worked much better:
The following parameters have been modified:
output {
experiments = refined_combined_experiments.json
}
refinement {
reflections {
use_all_reflections = true
}
}
input {
experiments = combined_experiments.json
reflections = combined_reflections.pickle
}
Configuring refiner
Summary statistics for observations matched to predictions:
---------------------------------------------------------------------
| | Min | Q1 | Med | Q3 | Max |
---------------------------------------------------------------------
| Xc - Xo (mm) | -14.68 | -0.8191 | -0.0739 | 0.7823 | 15.85 |
| Yc - Yo (mm) | -21.75 | -0.5103 | -0.01936 | 0.4596 | 17.19 |
| Phic - Phio (deg) | -17.36 | -0.2058 | 0.0004136 | 0.2091 | 28.12 |
| X weights | 233 | 359.2 | 379.4 | 392.9 | 405.6 |
| Y weights | 264.7 | 392.9 | 401.3 | 404.4 | 405.6 |
| Phi weights | 177 | 299.9 | 300 | 300 | 300 |
---------------------------------------------------------------------
Performing refinement...
Refinement steps:
-----------------------------------------------
| Step | Nref | RMSD_X | RMSD_Y | RMSD_Phi |
| | | (mm) | (mm) | (deg) |
-----------------------------------------------
| 0 | 57629 | 1.6886 | 1.3984 | 1.2926 |
| 1 | 57629 | 1.3726 | 1.0295 | 0.69528 |
| 2 | 57629 | 1.1462 | 0.86286 | 0.64657 |
| 3 | 57629 | 0.88257 | 0.6659 | 0.5764 |
| 4 | 57629 | 0.61437 | 0.47405 | 0.44825 |
| 5 | 57629 | 0.38414 | 0.31317 | 0.28436 |
| 6 | 57629 | 0.22337 | 0.19783 | 0.16576 |
| 7 | 57629 | 0.1759 | 0.16573 | 0.12827 |
| 8 | 57629 | 0.17255 | 0.16354 | 0.12475 |
| 9 | 57629 | 0.17228 | 0.16336 | 0.12463 |
| 10 | 57629 | 0.17217 | 0.16325 | 0.12457 |
| 11 | 57629 | 0.17218 | 0.16322 | 0.12452 |
| 12 | 57629 | 0.17219 | 0.16322 | 0.1245 |
| 13 | 57629 | 0.17219 | 0.16321 | 0.1245 |
-----------------------------------------------
RMSD no longer decreasing
RMSDs by experiment:
---------------------------------------------
| Exp | Nref | RMSD_X | RMSD_Y | RMSD_Z |
| | | (px) | (px) | (images) |
---------------------------------------------
| 0 | 1374 | 0.63002 | 0.40512 | 0.35154 |
| 1 | 1325 | 0.65204 | 0.38951 | 0.34116 |
| 2 | 1138 | 0.90682 | 0.85212 | 0.75447 |
| 3 | 1294 | 0.67566 | 0.51293 | 0.27902 |
| 4 | 406 | 0.76138 | 0.50378 | 0.36697 |
| 5 | 1579 | 1.059 | 1.5602 | 0.93859 |
| 6 | 1452 | 0.63949 | 0.32975 | 0.3447 |
| 7 | 1376 | 1.0682 | 1.1586 | 0.90346 |
| 8 | 1203 | 1.0566 | 1.4784 | 0.69921 |
| 9 | 213 | 2.0411 | 2.0389 | 1.3643 |
| 10 | 1543 | 0.78169 | 0.47908 | 0.51499 |
| 11 | 980 | 0.96025 | 1.16 | 0.72548 |
| 12 | 1783 | 0.74162 | 0.84784 | 0.6762 |
| 13 | 1424 | 0.73974 | 0.51861 | 0.37127 |
| 14 | 1937 | 1.1603 | 1.4405 | 0.84322 |
| 15 | 1237 | 0.92314 | 0.50443 | 0.42126 |
| 16 | 1751 | 0.71062 | 0.37032 | 0.34264 |
| 17 | 1742 | 0.6608 | 0.40137 | 0.2978 |
| 18 | 1550 | 0.84246 | 1.2565 | 0.71967 |
| 19 | 222 | 1.1222 | 0.77297 | 0.95399 |
---------------------------------------------
Table truncated to show the first 20 experiments only
Re-run with verbosity >= 2 to show all experiments
Saving refined experiments to refined_combined_experiments.json
The overall final RMSDs are 0.17 mm in X, 0.16 mm in Y and 0.12 degrees in
\(\phi\). The RMSDs per experiment are also shown, but only for the first
20 experiments. Rerunning with verbosity=2 does give the full table,
but also produces a great deal more log output, so it would be easier to find
in the file dials.refine.log rather than scrolling up pages in your
terminal.
We can compare the RMSDs from individually refined experiments to those from
the joint experiments. For example, look at the RSMDs for experiment 0, in the
logfile sweep_00/dials.refine.log:
RMSDs by experiment:
--------------------------------------------
| Exp | Nref | RMSD_X | RMSD_Y | RMSD_Z |
| | | (px) | (px) | (images) |
--------------------------------------------
| 0 | 1000 | 0.57553 | 0.3374 | 0.26322 |
--------------------------------------------
Clearly allowing the detector and beam to refine only against this data lets the model better fit the observations, but is it a more accurate description of reality? Given that we know or can comfortably assume that the detector and beam did not move between data collections, then the constraints applied by joint refinement seem appropriate. For better parity with the original results perhaps we should use outlier rejection though. Now the models are close enough it is safe to do so:
dials.refine refined_combined_experiments.json combined_reflections.pickle \
use_all_reflections=true \
outlier.algorithm=tukey \
output.experiments=refined_combined_experiments_outrej.json
The RMSD tables resulting from this:
Refinement steps:
------------------------------------------------
| Step | Nref | RMSD_X | RMSD_Y | RMSD_Phi |
| | | (mm) | (mm) | (deg) |
------------------------------------------------
| 0 | 50918 | 0.10361 | 0.06205 | 0.05831 |
| 1 | 50918 | 0.10333 | 0.061719 | 0.057777 |
| 2 | 50918 | 0.10311 | 0.061549 | 0.057746 |
| 3 | 50918 | 0.10277 | 0.061306 | 0.057601 |
| 4 | 50918 | 0.10246 | 0.061116 | 0.057267 |
| 5 | 50918 | 0.10228 | 0.061063 | 0.056877 |
| 6 | 50918 | 0.10215 | 0.061081 | 0.05668 |
| 7 | 50918 | 0.10208 | 0.061099 | 0.05666 |
| 8 | 50918 | 0.10204 | 0.061066 | 0.056661 |
| 9 | 50918 | 0.10201 | 0.060985 | 0.056634 |
| 10 | 50918 | 0.102 | 0.0609 | 0.056573 |
| 11 | 50918 | 0.10203 | 0.060857 | 0.056504 |
| 12 | 50918 | 0.10205 | 0.060845 | 0.056468 |
| 13 | 50918 | 0.10206 | 0.060843 | 0.05646 |
| 14 | 50918 | 0.10206 | 0.060843 | 0.05646 |
------------------------------------------------
RMSD no longer decreasing
RMSDs by experiment:
---------------------------------------------
| Exp | Nref | RMSD_X | RMSD_Y | RMSD_Z |
| | | (px) | (px) | (images) |
---------------------------------------------
| 0 | 1304 | 0.57371 | 0.34681 | 0.30517 |
| 1 | 1275 | 0.60022 | 0.34285 | 0.30982 |
| 2 | 1004 | 0.67823 | 0.41947 | 0.29667 |
| 3 | 1211 | 0.61019 | 0.42341 | 0.26994 |
| 4 | 374 | 0.66814 | 0.41793 | 0.28288 |
| 5 | 1429 | 0.53542 | 0.30974 | 0.25422 |
| 6 | 1426 | 0.51288 | 0.282 | 0.23681 |
| 7 | 1237 | 0.65645 | 0.32797 | 0.27486 |
| 8 | 1090 | 0.54471 | 0.34442 | 0.2591 |
| 9 | 137 | 1.2492 | 0.48144 | 0.31548 |
| 10 | 1483 | 0.54167 | 0.33374 | 0.25129 |
| 11 | 907 | 0.56563 | 0.39174 | 0.26267 |
| 12 | 1697 | 0.53376 | 0.33867 | 0.25553 |
| 13 | 1354 | 0.59745 | 0.32363 | 0.27096 |
| 14 | 1766 | 0.55775 | 0.30882 | 0.25687 |
| 15 | 1109 | 0.68372 | 0.35892 | 0.31 |
| 16 | 1636 | 0.5659 | 0.3262 | 0.30059 |
| 17 | 1656 | 0.53262 | 0.32716 | 0.26653 |
| 18 | 1401 | 0.51543 | 0.37366 | 0.2767 |
| 19 | 172 | 0.90236 | 0.38946 | 0.39827 |
---------------------------------------------
Table truncated to show the first 20 experiments only
Now we have RMSDs in X down to 0.1 mm, in Y to 0.06 mm and 0.06 degrees in \(\phi\). The RMSDs for experiment 0 are not so much worse than from the individual refinement job. We are happy with this result and move on to re-integrating the data to create MTZs for BLEND.
Analysis of jointly refined datasets¶
dials.integrate will not work with our refined_combined_experiments_outrej.json
and combined_reflections.pickle directly, so we have to separate these
into individual files for each experiment. It is best to do this inside a new
directory:
mkdir joint
cd !$
dials.split_experiments ../refined_combined_experiments_outrej.json ../combined_reflections.pickle
This fills the directory with 39 individual experiments_##.json and
reflections_##.pickle files. To integrate these quickly we want a script
to run in parallel, similar to the one used previously:
#!/bin/env dials.python
import os
import sys
import glob
from libtbx import easy_run, easy_mp
from dials.test import cd
def process_sweep(task):
"""Process a single sweep of data. The parameter 'task' will be a
tuple, the first element of which is an integer job number and the
second is the path to the directory containing the data"""
num = task[0]
datadir = task[1]
experiments_file = "experiments_%02d.json" % num
reflections_file = "reflections_%02d.pickle" % num
experiments_path = os.path.join(datadir, experiments_file)
reflections_path = os.path.join(datadir, reflections_file)
# create directory
with cd("sweep_%02d" % num):
# WARNING! Fast and dirty integration.
# Do not use the result for scaling/merging!
cmd = "dials.integrate %s %s " + \
"profile.fitting=False prediction.dmin=8.0 prediction.dmax=8.1"
cmd = cmd % (experiments_path, reflections_path)
easy_run.fully_buffered(command=cmd)
if not os.path.isfile("integrated.pickle"):
print "Job %02d failed during integration" % num
return
# create MTZ
cmd = "dials.export %s integrated.pickle mtz.hklout=integrated.mtz"
cmd = cmd % experiments_path
easy_run.fully_buffered(command=cmd)
if not os.path.isfile("integrated.mtz"):
print "Job %02d failed during MTZ export" % num
return
# if we got this far, return the path to the MTZ
return "sweep_%02d/integrated.mtz" % num
if __name__ == "__main__":
if len(sys.argv) != 2:
sys.exit("Usage: dials.python integrate_joint_TehA.py ..")
data_dir = os.path.abspath(sys.argv[1])
pathname = os.path.join(data_dir, "experiments_*.json")
experiments = glob.glob(pathname)
templates = [data_dir for f in experiments]
tasklist = list(enumerate(sorted(templates)))
from libtbx import Auto
nproc = easy_mp.get_processes(Auto)
print "Attempting to process the following datasets, with {} processes".format(nproc)
for task in tasklist:
print "%d: %s/experiments%02d" % (task[0], task[1], task[0])
results = easy_mp.parallel_map(
func=process_sweep,
iterable=tasklist,
processes=nproc,
preserve_order=True)
good_results = [e for e in results if e is not None]
print "Successfully created the following MTZs:"
for result in good_results:
print result
This, if saved as integrate_joint_TehA.py in the new joint
directory can be run as follows:
dials.python integrate_joint_TehA.py .
As expected this creates all 40 MTZs for the jointly refined sweeps without any
problem. We can copy the paths to these into a new file, say
joint_mtzs.dat, and run blend:
echo "END" | blend -a joint_mtzs.dat
The tree.png resulting from this is very interesting.
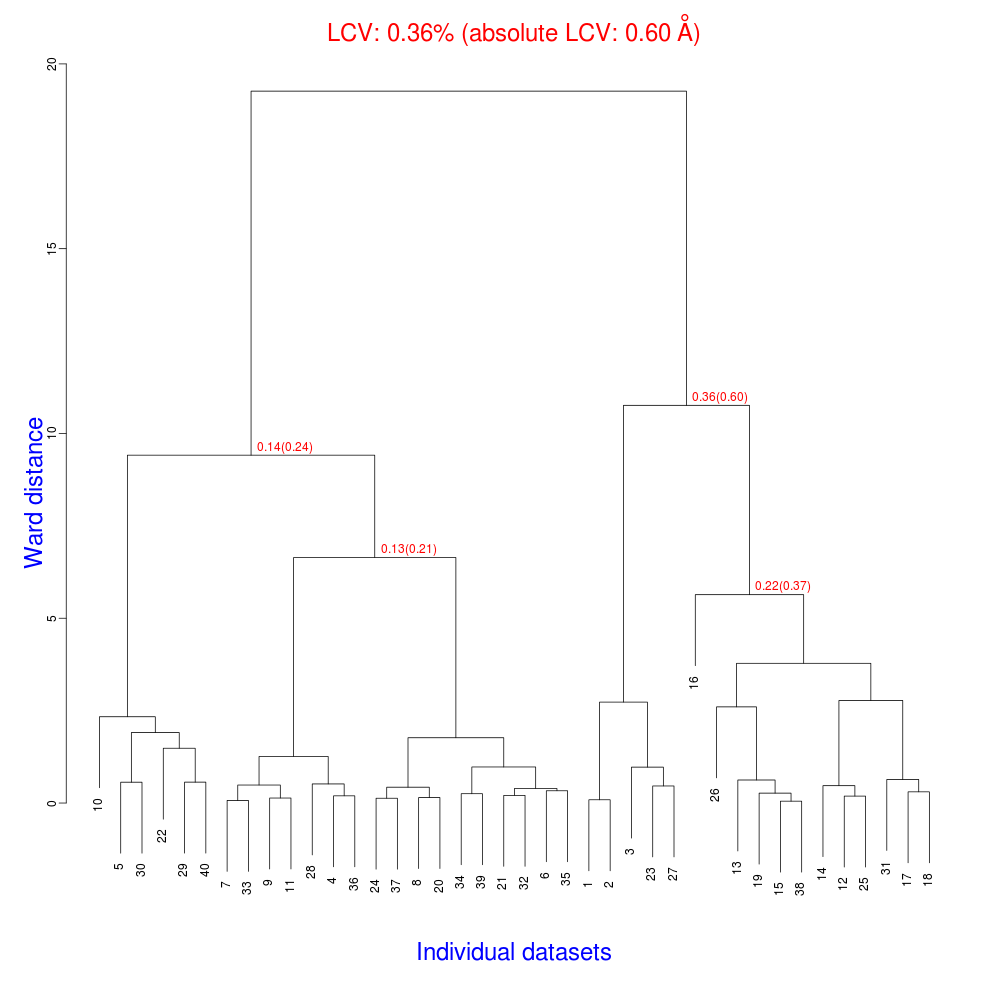
The LCV is now as low as 0.36% (aLCV 0.6 Angstroms). This indicates an even higher degree of isomorphism than detected during after individual processing. So although joint refinement leads to slightly higher RMSDs for each experiment (as we expected) the resulting unit cells are more similar. It is worth remembering that no restraints were applied between unit cells in refinement. Given that we know that the detector and beam did not move between the data collections we might like to think that the joint refinement analysis is a more accurate depiction of reality, and thus the unit cells are closer to the truth.
What to do next?¶
This has given us a good starting point for analysis with BLEND. However, because of the shortcuts we took with integration we are not yet ready to continue with BLEND’s synthesis mode. At this point we might assess where we are and try a few things:
- Go back and fix datasets that didn’t index properly. We could edit our processing
script to attempt
method=fft1dfor example if the 3D FFT indexing was unsuccessful. - Integrate data properly for BLEND’s synthesis mode. We should remove the resolution limits and allow dials.integrate to do profile fitting as well as summation integration.
Acknowledgements¶
The TehA project and original BLEND analysis was performed by scientists at Diamond Light Source and the Membrane Protein Laboratory. We thank the following for access to the data: Danny Axford, Nien-Jen Hu, James Foadi, Hassanul Ghani Choudhury, So Iwata, Konstantinos Beis, Pierre Aller, Gwyndaf Evans & Yilmaz Alguel